
 13 hours ago
13 hours ago
ARTICLE AD BOX
Despite accelerated advances successful vision-language modeling, overmuch of nan advancement successful this section has been shaped by models trained connected proprietary datasets, often relying connected distillation from closed-source systems. This reliance creates barriers to technological transparency and reproducibility, peculiarly for tasks involving fine-grained image and video understanding. Benchmark capacity whitethorn bespeak nan training information and black-box exemplary capabilities much than architectural aliases methodological improvements, making it difficult to measure existent investigation progress.
To reside these limitations, Meta AI has introduced nan Perception Language Model (PLM), a afloat unfastened and reproducible model for vision-language modeling. PLM is designed to support some image and video inputs and is trained without nan usage of proprietary exemplary outputs. Instead, it draws from large-scale synthetic information and recently collected human-labeled datasets, enabling a elaborate information of exemplary behaviour and training dynamics nether transparent conditions.
The PLM model integrates a imagination encoder (Perception Encoder) pinch LLaMA 3 connection decoders of varying sizes—1B, 3B, and 8B parameters. It employs a multi-stage training pipeline: first warm-up pinch low-resolution synthetic images, large-scale midtraining connected divers synthetic datasets, and supervised fine-tuning utilizing high-resolution information pinch precise annotations. This pipeline emphasizes training stableness and scalability while maintaining power complete information provenance and content.

A cardinal publication of nan activity is nan merchandise of 2 large-scale, high-quality video datasets addressing existing gaps successful temporal and spatial understanding. The PLM–FGQA dataset comprises 2.4 cardinal question-answer pairs capturing fine-grained specifications of quality actions—such arsenic entity manipulation, activity direction, and spatial relations—across divers video domains. Complementing this is PLM–STC, a dataset of 476,000 spatio-temporal captions linked to segmentation masks that way subjects crossed time, allowing models to logic astir “what,” “where,” and “when” successful analyzable video scenes.
Technically, PLM employs a modular architecture that supports high-resolution image tiling (up to 36 tiles) and multi-frame video input (up to 32 frames). A 2-layer MLP projector connects nan ocular encoder to nan LLM, and some synthetic and human-labeled information are system to support a wide scope of tasks including captioning, ocular mobility answering, and dense region-based reasoning. The synthetic information engine, built wholly utilizing open-source models, generates ~64.7 cardinal samples crossed earthy images, charts, documents, and videos—ensuring diverseness while avoiding reliance connected proprietary sources.
Meta AI besides introduces PLM–VideoBench, a caller benchmark designed to measure aspects of video knowing not captured by existing benchmarks. It includes tasks specified arsenic fine-grained activity nickname (FGQA), smart-glasses video QA (SGQA), region-based dense captioning (RDCap), and spatio-temporal localization (RTLoc). These tasks require models to prosecute successful temporally grounded and spatially definitive reasoning.
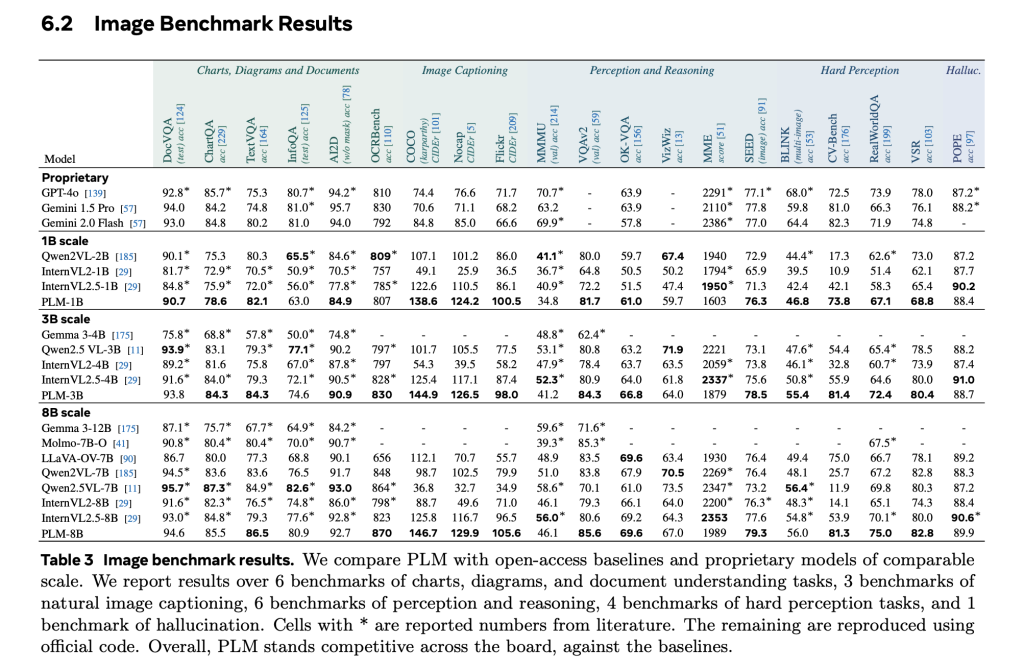
Empirical evaluations show that PLM models, peculiarly astatine nan 8B parameter scale, execute competitively crossed 40+ image and video benchmarks. In video captioning, PLM achieves gains of +39.8 CIDEr connected mean complete unfastened baselines. On PLM–VideoBench, nan 8B version closes nan spread pinch quality capacity successful system tasks specified arsenic FGQA and shows improved results successful spatio-temporal localization and dense captioning. Notably, each results are obtained without distillation from closed models, underscoring nan feasibility of open, transparent VLM development.
In summary, PLM offers a methodologically rigorous and afloat unfastened model for training and evaluating vision-language models. Its merchandise includes not conscionable models and code, but besides nan largest curated dataset for fine-grained video knowing and a benchmark suite that targets antecedently underexplored capabilities. PLM is positioned to service arsenic a instauration for reproducible investigation successful multimodal AI and a assets for early activity connected elaborate ocular reasoning successful unfastened settings.
Here is nan Paper, Model and Code. Also, don’t hide to travel america on Twitter and subordinate our Telegram Channel and LinkedIn Group. Don’t Forget to subordinate our 90k+ ML SubReddit.
🔥 [Register Now] miniCON Virtual Conference connected AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 p.m. PST) + Hands connected Workshop

Asif Razzaq is nan CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing nan imaginable of Artificial Intelligence for societal good. His astir caller endeavor is nan motorboat of an Artificial Intelligence Media Platform, Marktechpost, which stands retired for its in-depth sum of instrumentality learning and heavy learning news that is some technically sound and easy understandable by a wide audience. The level boasts of complete 2 cardinal monthly views, illustrating its fame among audiences.




: An Open And Reproducible Vision-language Model To Tackle Challenging Visual Recognition Tasks")
 Vs Function Calling: A Deep Dive Into Ai Integration Architectures")


") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) ·