
 1 day ago
1 day ago
ARTICLE AD BOX
The Challenge of Designing General-Purpose Vision Encoders
As AI systems turn progressively multimodal, nan domiciled of ocular cognition models becomes much complex. Vision encoders are expected not only to admit objects and scenes, but besides to support tasks for illustration captioning, mobility answering, fine-grained recognition, archive parsing, and spatial reasoning crossed some images and videos. Existing models typically trust connected divers pretraining objectives—contrastive learning for retrieval, captioning for connection tasks, and self-supervised methods for spatial understanding. This fragmentation complicates scalability and exemplary deployment, and introduces trade-offs successful capacity crossed tasks.
What remains a cardinal situation is nan creation of a unified imagination encoder that tin lucifer aliases transcend task-specific methods, run robustly successful open-world scenarios, and standard efficiently crossed modalities.
A Unified Solution: Meta AI’s Perception Encoder
Meta AI introduces Perception Encoder (PE), a imagination exemplary family trained utilizing a azygous contrastive vision-language nonsubjective and refined pinch alignment techniques tailored for downstream tasks. PE departs from nan accepted multi-objective pretraining paradigm. Instead, it demonstrates that pinch a cautiously tuned training look and due alignment methods, contrastive learning unsocial tin output highly generalizable ocular representations.
The Perception Encoder operates crossed 3 scales—PEcoreB, PEcoreL, and PEcoreG—with nan largest (G-scale) exemplary containing 2B parameters. These models are designed to usability arsenic general-purpose encoders for some image and video inputs, offering beardown capacity successful classification, retrieval, and multimodal reasoning.
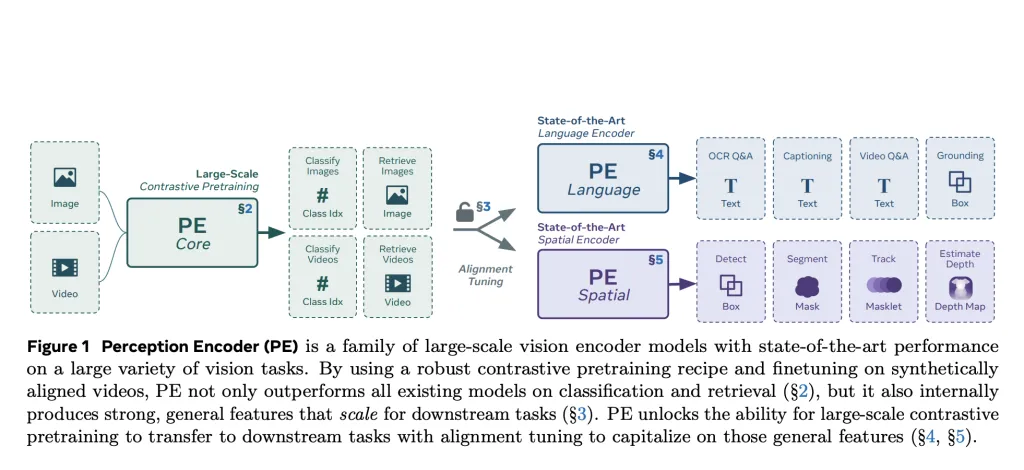
Training Approach and Architecture
The pretraining of PE follows a two-stage process. The first shape involves robust contrastive learning connected a large-scale curated image-text dataset (5.4B pairs), wherever respective architectural and training enhancements amended some accuracy and robustness. These see progressive solution scaling, ample batch sizes (up to 131K), usage of nan LAMB optimizer, 2D RoPE positional encoding, tuned augmentations, and masked regularization.
The 2nd shape introduces video knowing by leveraging a video information engine that synthesizes high-quality video-text pairs. This pipeline incorporates captions from nan Perception Language Model (PLM), frame-level descriptions, and metadata, which are past summarized utilizing Llama 3.3. These synthetic annotations let nan aforesaid image encoder to beryllium fine-tuned for video tasks via framework averaging.
Despite utilizing a azygous contrastive objective, PE features general-purpose representations distributed crossed intermediate layers. To entree these, Meta introduces 2 alignment strategies:
- Language alignment for tasks specified arsenic ocular mobility answering and captioning.
- Spatial alignment for detection, tracking, and extent estimation, utilizing self-distillation and spatial correspondence distillation via SAM2.
Empirical Performance Across Modalities
PE demonstrates beardown zero-shot generalization crossed a wide scope of imagination benchmarks. On image classification, PEcoreG matches aliases exceeds proprietary models trained connected ample backstage datasets specified arsenic JFT-3B. It achieves:
- 86.6% connected ImageNet-val,
- 92.6% connected ImageNet-Adversarial,
- 88.2% connected nan afloat ObjectNet set,
- Competitive results connected fine-grained datasets including iNaturalist, Food101, and Oxford Flowers.
In video tasks, PE achieves state-of-the-art capacity connected zero-shot classification and retrieval benchmarks, outperforming InternVideo2 and SigLIP2-g-opt, while being trained connected conscionable 22M synthetic video-caption pairs. The usage of elemental mean pooling crossed frames—rather than temporal attention—demonstrates that architectural simplicity, erstwhile paired pinch well-aligned training data, tin still output high-quality video representations.
An ablation study shows that each constituent of nan video information motor contributes meaningfully to performance. Improvements of +3.9% successful classification and +11.1% successful retrieval complete image-only baselines item nan inferior of synthetic video data, moreover astatine humble scale.
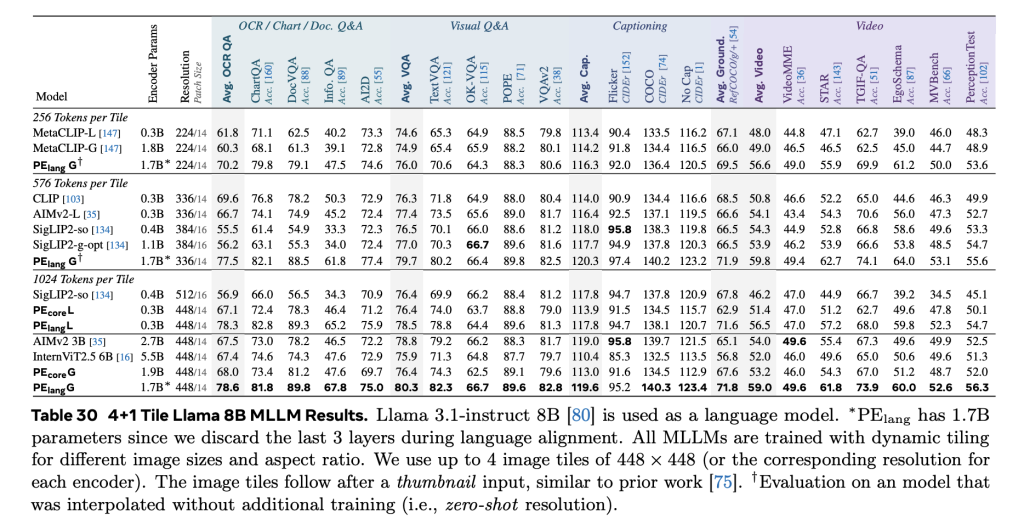
Conclusion
Perception Encoder provides a technically compelling objection that a azygous contrastive objective, if implemented pinch attraction and paired pinch thoughtful alignment strategies, is capable to build general-purpose imagination encoders. PE not only matches specialized models successful their respective domains but does truthful pinch a unified and scalable approach.
The merchandise of PE, on pinch its codebase and nan PE Video Dataset, offers nan investigation organization a reproducible and businesslike instauration for building multimodal AI systems. As ocular reasoning tasks turn successful complexity and scope, PE provides a way guardant toward much integrated and robust ocular understanding.
Check retired nan Paper, Model, Code and Dataset. Also, don’t hide to travel america on Twitter and subordinate our Telegram Channel and LinkedIn Group. Don’t Forget to subordinate our 90k+ ML SubReddit.
🔥 [Register Now] miniCON Virtual Conference connected AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 p.m. PST) + Hands connected Workshop

Asif Razzaq is nan CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing nan imaginable of Artificial Intelligence for societal good. His astir caller endeavor is nan motorboat of an Artificial Intelligence Media Platform, Marktechpost, which stands retired for its in-depth sum of instrumentality learning and heavy learning news that is some technically sound and easy understandable by a wide audience. The level boasts of complete 2 cardinal monthly views, illustrating its fame among audiences.



: An Open And Reproducible Vision-language Model To Tackle Challenging Visual Recognition Tasks")
 Pro, A Fresh Take On A Smartphone Design For A Great Price")
 Vs Function Calling: A Deep Dive Into Ai Integration Architectures")

") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) · 