
 1 month ago
1 month ago
ARTICLE AD BOX
A captious advancement successful caller times has been exploring reinforcement learning (RL) techniques to amended LLMs beyond accepted supervised fine-tuning methods. RL allows models to study optimal responses done reward signals, enhancing their reasoning and decision-making capabilities. RL introduces a feedback-driven training loop that amended aligns pinch human-like learning processes, peculiarly successful tasks involving step-by-step problem-solving aliases mathematics reasoning. This intersection of LLMs and RL is becoming a salient area for world investigation and manufacture innovation.
A cardinal situation successful improving LLMs for analyzable reasoning tasks is ensuring these models create amended reasoning skills alternatively than longer outputs. In reinforcement learning-based training of LLMs, a shape has emerged wherever models statesman generating excessively agelong responses without needfully improving reply quality. This raises concerns astir optimization biases successful RL methods that whitethorn favour verbosity complete correctness. Another complication arises from nan guidelines models themselves; immoderate already show signs of reasoning capabilities, which makes it difficult to isolate nan existent effect of RL tuning. Therefore, knowing really training strategies and exemplary foundations impact last capacity becomes essential.
Previously, reinforcement learning post-training for LLMs often relied connected algorithms for illustration Proximal Policy Optimization (PPO), commonly utilized successful various open-source implementations. These implementations often included a response-length normalization step, which inadvertently introduced biases favoring longer aliases shorter outputs depending connected nan correctness of nan response. In particular, Group Relative Policy Optimization (GRPO) was introduced arsenic a version to optimize argumentation updates astatine nan group level. While effective, GRPO has been criticized for embedding subtle optimization biases that impact nan magnitude and value of exemplary responses. These existing techniques, though innovative, person shown limitations that obscure nan existent gains from reinforcement learning.
Researchers from Sea AI Lab, nan National University of Singapore, and Singapore Management University introduced a caller attack called Dr. GRPO (Group Relative Policy Optimization Done Right) to reside these issues. This method removes nan problematic normalization position from nan GRPO formulation. Specifically, it eliminates nan consequence magnitude and modular deviation scaling factors that caused imbalances successful exemplary updates. The revised algorithm computes gradients much reasonably crossed different responses and mobility types. They applied this method to train Qwen2.5-Math-7B, an open-source guidelines exemplary and demonstrated its effectiveness connected aggregate benchmarks. The training process utilized 27 hours of computing connected 8× A100 GPUs, a comparatively humble setup considering nan results achieved.
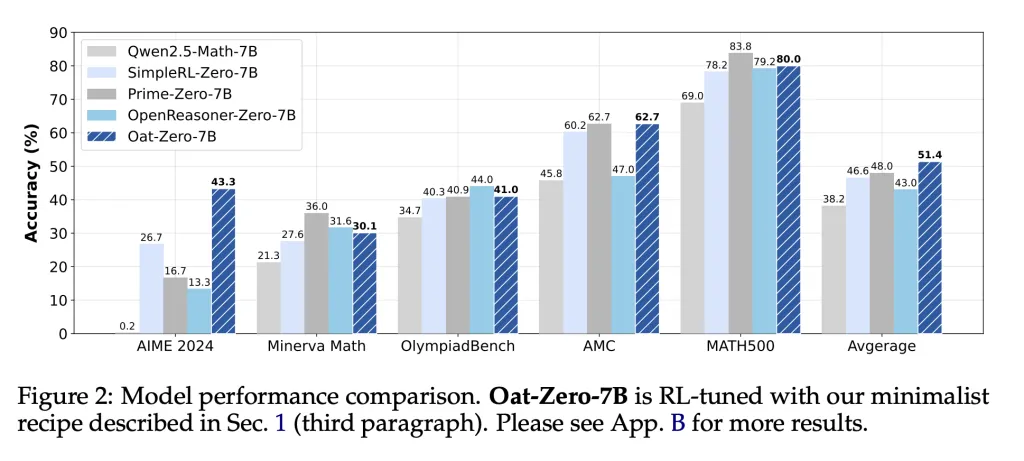
The researchers tested their method connected salient mathematics reasoning benchmarks, including AIME 2024, AMC, MATH500, Minerva Math, and OlympiadBench. The exemplary trained pinch Dr. GRPO achieved 43.3% accuracy connected AIME 2024, importantly outperforming SimpleRL-Zero-7B (36.0%), Prime-Zero-7B (27.6%), and OpenReasoner-Zero-7B (16.7%). It besides demonstrated beardown mean capacity crossed each tasks: 40.9% connected MATH500, 45.8% connected Minerva, and 62.7% connected OlympiadBench. These results validate nan effectiveness of nan bias-free RL method. Importantly, nan exemplary performed amended and showed much businesslike token usage. Incorrect responses became shorter and much focused, a notable displacement from erstwhile training methods encouraging overextended answers sloppy of correctness.

Beyond nan training algorithm, nan squad besides examined nan quality of guidelines models utilized successful R1-Zero-like RL settings. They recovered that immoderate models, specified arsenic Qwen2.5, show precocious capabilities moreover earlier training, perchance owed to pretraining connected concatenated question-answer data. For example, nan Qwen2.5-Math-7B exemplary achieved 38.2% mean accuracy without immoderate RL fine-tuning, outperforming galore models trained utilizing accepted methods. This preexisting reasoning capacity complicates claims astir nan benefits of RL, arsenic improvements whitethorn partially stem from anterior training strategies alternatively than caller learning done reinforcement. DeepSeek-V3-Base, different examined model, showed spontaneous “Aha moments” and instances of self-reflection earlier RL, further suggesting that immoderate reasoning skills whitethorn already beryllium embedded successful guidelines models.
The capacity dynamics were cautiously tracked during training. Using Dr. GRPO, models avoided nan inclination to inflate consequence lengths. The information revealed that Dr. GRPO kept output lengths unchangeable while expanding reward signals, suggesting a nonstop relationship betwixt training and improved accuracy, not conscionable verbosity. In contrast, accepted GRPO led to progressively longer incorrect responses, falsely indicating improvement. This study aligns pinch findings that galore open-source PPO implementations unwittingly present response-length bias, a flaw inherited from pretraining practices.

The researchers besides explored really different templates and mobility sets power exemplary behavior. The Qwen2.5-Math-1.5B guidelines exemplary performed champion without punctual templates, scoring 61.6% connected Minerva Math and 45.8% connected MATH500. Surprisingly, utilizing templates often decreased capacity earlier RL recovered it. This highlights really mismatches betwixt exemplary pretraining and conclusion format tin obscure existent reasoning capabilities. Also, models trained connected small, elemental mobility sets for illustration GSM-8K often outperformed those trained connected larger datasets, challenging nan presumption that broader sum ever leads to amended reasoning.
Several Key Takeaways from nan Research see nan following:
- DeepSeek-V3-Base and Qwen2.5 models grounds reasoning capabilities moreover earlier RL, indicating beardown pretraining effects.
- Dr. GRPO eliminates biases successful GRPO by removing magnitude and reward normalization terms, improving token efficiency.
- The Qwen2.5-Math-7B model, trained pinch Dr. GRPO, achieved:
- 43.3% connected AIME 2024
- 62.7% connected OlympiadBench
- 45.8% connected Minerva Math
- 40.9% connected MATH500
- The mean people crossed each benchmarks: 40.3%
- Incorrect responses were importantly shorter utilizing Dr. GRPO, avoiding unnecessary verbosity seen successful different methods.
- Qwen2.5 models execute amended without punctual templates, suggesting they whitethorn beryllium pretrained connected Q&A formatted data.
- Smaller mobility sets for illustration GSM-8K tin execute amended than larger ones, countering expectations.
- Open-source PPO implementations often incorporate unintended response-length biases that Dr. GRPO successfully removes.
In conclusion, nan study reveals captious insights into really RL affects ample connection exemplary behavior. Researchers recovered that pretraining plays a important domiciled successful determining baseline capabilities. They besides demonstrated that optimization biases successful celebrated RL algorithms tin mislead training and evaluation. The preamble of Dr. GRPO corrected these issues, starring to much interpretable and businesslike exemplary training. With only 27 hours of training, their exemplary reached state-of-the-art results connected awesome mathematics reasoning benchmarks. These findings reshape really nan organization should measure RL-enhanced LLMs, focusing much connected method transparency and guidelines exemplary characteristics than connected specified capacity metrics.
Check out the Paper and GitHub Page. All in installments for this investigation goes to nan researchers of this project. Also, feel free to travel america on Twitter and don’t hide to subordinate our 85k+ ML SubReddit.

Asif Razzaq is nan CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing nan imaginable of Artificial Intelligence for societal good. His astir caller endeavor is nan motorboat of an Artificial Intelligence Media Platform, Marktechpost, which stands retired for its in-depth sum of instrumentality learning and heavy learning news that is some technically sound and easy understandable by a wide audience. The level boasts of complete 2 cardinal monthly views, illustrating its fame among audiences.





 Rhd Video In Melbourne, Australia !")


") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) · 