
 4 hours ago
4 hours ago
ARTICLE AD BOX
A caller collaboration betwixt University of California Merced and Adobe offers an beforehand connected nan state-of-the-art successful human image completion – nan much-studied task of ‘de-obscuring' occluded aliases hidden parts of images of people, for purposes specified arsenic virtual try-on, animation and photo-editing.

Besides repairing damaged images aliases changing them astatine a user's whim, quality image completion systems specified arsenic CompleteMe tin enforce caller clothing (via an adjunct reference image, arsenic successful nan mediate file successful these 2 examples) into existing images. These examples are from nan extended supplementary PDF for nan caller paper. Source: https://liagm.github.io/CompleteMe/pdf/supp.pdf
The new approach, titled CompleteMe: Reference-based Human Image Completion, uses supplementary input images to ‘suggest' to nan strategy what contented should switch nan hidden aliases missing conception of nan quality depiction (hence nan applicability to fashion-based try-on frameworks):

The CompleteMe strategy tin conform reference contented to nan obscured aliases occluded portion of a quality image.
The caller strategy uses a dual U-Net architecture and a Region-Focused Attention (RFA) artifact that marshals resources to nan pertinent area of nan image restoration instance.
The researchers besides connection a caller and challenging benchmark strategy designed to measure reference-based completion tasks (since CompleteMe is portion of an existing and ongoing investigation strand successful machine vision, albeit 1 that has had nary benchmark schema until now).
In tests, and successful a well-scaled personification study, nan caller method came retired up successful astir metrics, and up overall. In definite cases, rival methods were utterly foxed by nan reference-based approach:

From nan supplementary material: nan AnyDoor method has peculiar trouble deciding really to construe a reference image.
The insubstantial states:
‘Extensive experiments connected our benchmark show that CompleteMe outperforms state-of-the-art methods, some reference-based and non-reference-based, successful position of quantitative metrics, qualitative results and personification studies.
‘Particularly successful challenging scenarios involving analyzable poses, intricate clothing patterns, and unique accessories, our exemplary consistently achieves superior ocular fidelity and semantic coherence.'
Sadly, nan project's GitHub presence contains nary code, nor promises any, and nan initiative, which besides has a humble project page, seems framed arsenic a proprietary architecture.

Further illustration of nan caller system's subjective capacity against anterior methods. More specifications later successful nan article.
Method
The CompleteMe model is underpinned by a Reference U-Net, which handles nan integration of nan ancillary worldly into nan process, and a cohesive U-Net, which accommodates a wider scope of processes for obtaining nan last result, arsenic illustrated successful nan conceptual schema below:
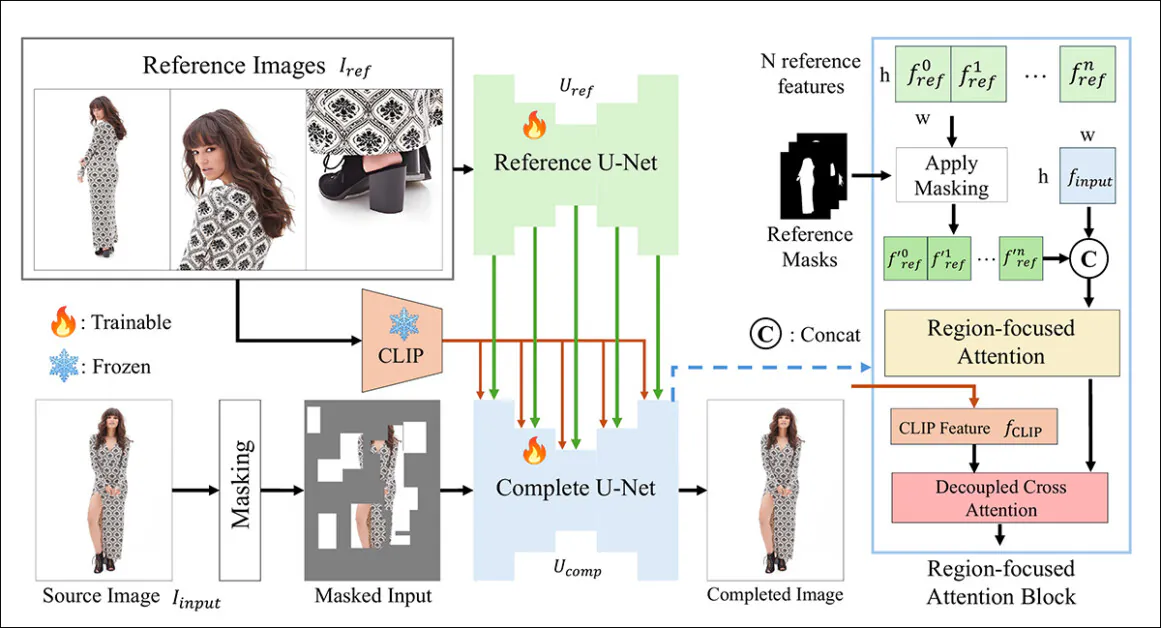
The conceptual schema for CompleteMe. Source: https://arxiv.org/pdf/2504.20042
The strategy first encodes nan masked input image into a latent representation. At nan aforesaid time, nan Reference U-Net processes aggregate reference images – each showing different assemblage regions – to extract elaborate spatial features.
These features walk done a Region-focused Attention artifact embedded successful nan ‘complete' U-Net, wherever they are selectively masked utilizing corresponding region masks, ensuring nan exemplary attends only to applicable areas successful nan reference images.
The masked features are past integrated pinch world CLIP-derived semantic features done decoupled cross-attention, allowing nan exemplary to reconstruct missing contented pinch some good item and semantic coherence.
To heighten realism and robustness, nan input masking process combines random grid-based occlusions pinch quality assemblage style masks, each applied pinch adjacent probability, expanding nan complexity of nan missing regions that nan exemplary must complete.
For Reference Only
Previous methods for reference-based image inpainting typically relied connected semantic-level encoders. Projects of this benignant see CLIP itself, and DINOv2, some of which extract world features from reference images, but often suffer nan good spatial specifications needed for meticulous personality preservation.

From nan merchandise insubstantial for nan older DINOV2 approach, which is included successful comparison tests successful nan caller study: The colored overlays show nan first 3 main components from Principal Component Analysis (PCA), applied to image patches wrong each column, highlighting really DINOv2 groups akin entity parts together crossed varied images. Despite differences successful pose, style, aliases rendering, corresponding regions (like wings, limbs, aliases wheels) are consistently matched, illustrating nan model's expertise to study part-based building without supervision. Source: https://arxiv.org/pdf/2304.07193
CompleteMe addresses this facet done a specialized Reference U-Net initialized from Stable Diffusion 1.5, but operating without nan diffusion sound step*.
Each reference image, covering different assemblage regions, is encoded into elaborate latent features done this U-Net. Global semantic features are besides extracted separately utilizing CLIP, and some sets of features are cached for businesslike usage during attention-based integration. Thus, nan strategy tin accommodate aggregate reference inputs flexibly, while preserving fine-grained quality information.
Orchestration
The cohesive U-Net manages nan last stages of nan completion process. Adapted from nan inpainting variant of Stable Diffusion 1.5, it takes arsenic input nan masked root image successful latent form, alongside elaborate spatial features drawn from nan reference images and world semantic features extracted by nan CLIP encoder.
These various inputs are brought together done nan RFA block, which plays a captious domiciled successful steering nan model’s attraction toward nan astir applicable areas of nan reference material.
Before entering nan attraction mechanism, nan reference features are explicitly masked to region unrelated regions and past concatenated pinch nan latent practice of nan root image, ensuring that attraction is directed arsenic precisely arsenic possible.
To heighten this integration, CompleteMe incorporates a decoupled cross-attention system adapted from nan IP-Adapter framework:

IP-Adapter, portion of which is incorporated into CompleteMe, is 1 of nan astir successful and often-leveraged projects from nan past 3 tumultuous years of improvement successful latent diffusion exemplary architectures. Source: https://ip-adapter.github.io/
This allows nan exemplary to process spatially elaborate ocular features and broader semantic discourse done abstracted attraction streams, which are later combined, resulting successful a coherent reconstruction that, nan authors contend, preserves some personality and fine-grained detail.
Benchmarking
In nan absence of an apposite dataset for reference-based quality completion, nan researchers person projected their own. The (unnamed) benchmark was constructed by curating prime image pairs from nan WPose dataset devised for Adobe Research's 2023 UniHuman project.

Examples of poses from nan Adobe Research 2023 UniHuman project. Source: https://github.com/adobe-research/UniHuman?tab=readme-ov-file#data-prep
The researchers manually drew root masks to bespeak nan inpainting areas, yet obtaining 417 tripartite image groups constituting a root image, mask, and reference image.

Two examples of groups derived initially from nan reference WPose dataset, and curated extensively by nan researchers of nan caller paper.
The authors utilized nan LLaVA Large Language Model (LLM) to make matter prompts describing nan root images.
Metrics utilized were much extended than usual; too nan accustomed Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM) and Learned Perceptual Image Patch Similarity (LPIPS, successful this lawsuit for evaluating masked regions), nan researchers utilized DINO for similarity scores; DreamSim for procreation consequence evaluation; and CLIP.
Data and Tests
To trial nan work, nan authors utilized some nan default Stable Diffusion V1.5 exemplary and nan 1.5 inpainting model. The system's image encoder utilized nan CLIP Vision model, together pinch projection layers – humble neural networks that reshape aliases align nan CLIP outputs to lucifer nan soul characteristic dimensions utilized by nan model.
Training took spot for 30,000 iterations complete 8 NVIDIA A100† GPUs, supervised by Mean Squared Error (MSE) loss, astatine a batch size of 64 and a learning rate of 2×10-5. Various elements were randomly dropped passim training, to forestall nan strategy overfitting connected nan data.
The dataset was modified from nan Parts to Whole dataset, itself based connected nan DeepFashion-MultiModal dataset.

Examples from nan Parts to Whole dataset, utilized successful nan improvement of nan curated information for CompleteMe. Source: https://huanngzh.github.io/Parts2Whole/
The authors state:
‘To meet our requirements, we [rebuilt] nan training pairs by utilizing occluded images pinch aggregate reference images that seizure various aspects of quality quality on pinch their short textual labels.
‘Each sample successful our training information includes six quality types: precocious assemblage clothes, little assemblage clothes, full assemblage clothes, hairsbreadth aliases headwear, face, and shoes. For nan masking strategy, we use 50% random grid masking betwixt 1 to 30 times, while for nan different 50%, we usage a quality assemblage style disguise to summation masking complexity.
‘After nan building pipeline, we obtained 40,000 image pairs for training.'
Rival anterior non-reference methods tested were Large occluded quality image completion (LOHC) and nan plug-and-play image inpainting exemplary BrushNet; reference-based models tested were Paint-by-Example; AnyDoor; LeftRefill; and MimicBrush.
The authors began pinch a quantitative comparison connected nan previously-stated metrics:
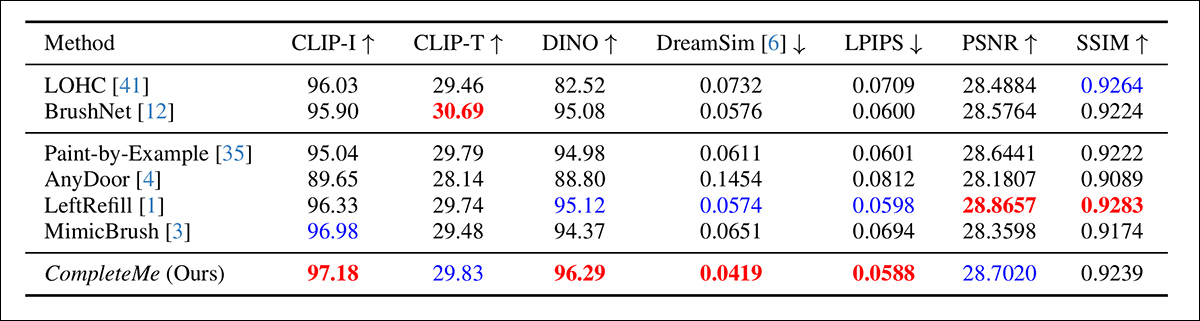
Results for nan first quantitative comparison.
Regarding nan quantitative evaluation, nan authors statement that CompleteMe achieves nan highest scores connected astir perceptual metrics, including CLIP-I, DINO, DreamSim, and LPIPS, which are intended to seizure semantic alignment and quality fidelity betwixt nan output and nan reference image.
However, nan exemplary does not outperform each baselines crossed nan board. Notably, BrushNet scores highest connected CLIP-T, LeftRefill leads successful SSIM and PSNR, and MimicBrush somewhat outperforms connected CLIP-I.
While CompleteMe shows consistently beardown results overall, nan capacity differences are humble successful immoderate cases, and definite metrics stay led by competing anterior methods. Perhaps not unfairly, nan authors framework these results arsenic grounds of CompleteMe’s balanced spot crossed some structural and perceptual dimensions.
Illustrations for nan qualitative tests undertaken for nan study are acold excessively galore to reproduce here, and we mention nan scholar not only to nan root paper, but to nan extended supplementary PDF, which contains galore further qualitative examples.
We item nan superior qualitative examples presented successful nan main paper, on pinch a action of further cases drawn from nan supplementary image excavation introduced earlier successful this article:

Initial qualitative results presented successful nan main paper. Please mention to nan root insubstantial for amended resolution.
Of nan qualitative results displayed above, nan authors comment:
‘Given masked inputs, these non-reference methods make plausible contented for nan masked regions utilizing image priors aliases matter prompts.
‘However, arsenic indicated successful nan Red box, they cannot reproduce circumstantial specifications specified arsenic tattoos aliases unsocial clothing patterns, arsenic they deficiency reference images to guideline nan reconstruction of identical information.'
A 2nd comparison, portion of which is shown below, focuses connected nan 4 reference-based methods Paint-by-Example, AnyDoor, LeftRefill, and MimicBrush. Here only 1 reference image and a matter punctual were provided.
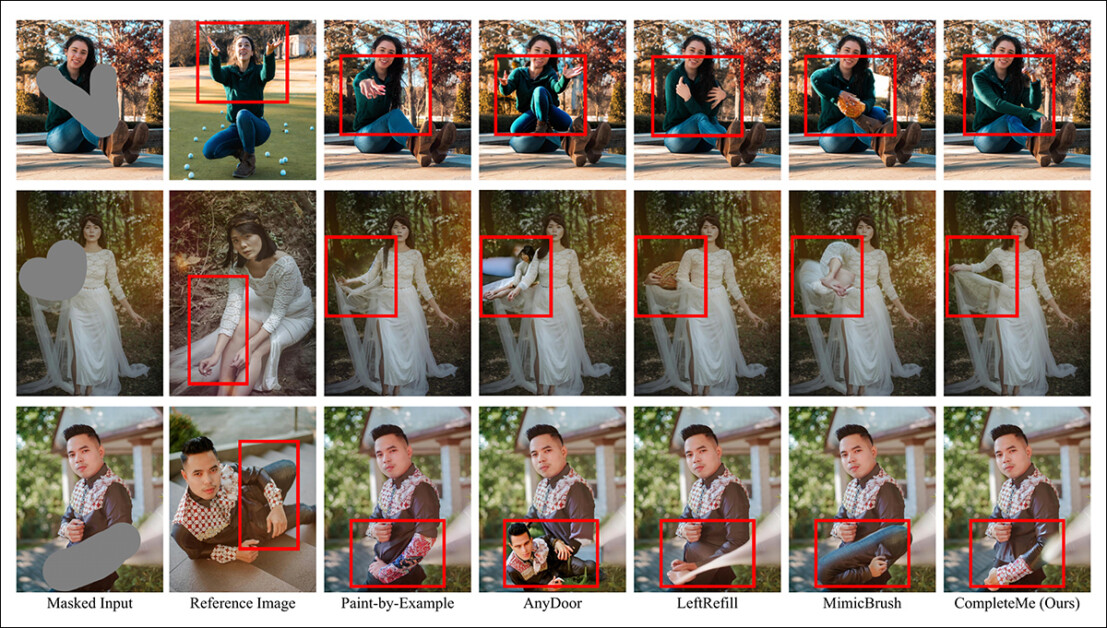
Qualitative comparison pinch reference-based methods. CompleteMe produces much realistic completions and amended preserves circumstantial specifications from nan reference image. The reddish boxes item areas of peculiar interest.
The authors state:
‘Given a masked quality image and a reference image, different methods tin make plausible contented but often neglect to sphere contextual accusation from nan reference accurately.
‘In immoderate cases, they make irrelevant contented aliases incorrectly representation corresponding parts from nan reference image. In contrast, CompleteMe efficaciously completes nan masked region by accurately preserving identical accusation and correctly mapping corresponding parts of nan quality assemblage from nan reference image.'
To measure really good nan models align pinch quality perception, nan authors conducted a personification study involving 15 annotators and 2,895 sample pairs. Each brace compared nan output of CompleteMe against 1 of 4 reference-based baselines: Paint-by-Example, AnyDoor, LeftRefill, aliases MimicBrush.
Annotators evaluated each consequence based connected nan ocular value of nan completed region and nan grade to which it preserved personality features from nan reference – and here, evaluating wide value and identity, CompleteMe obtained a much definitive result:
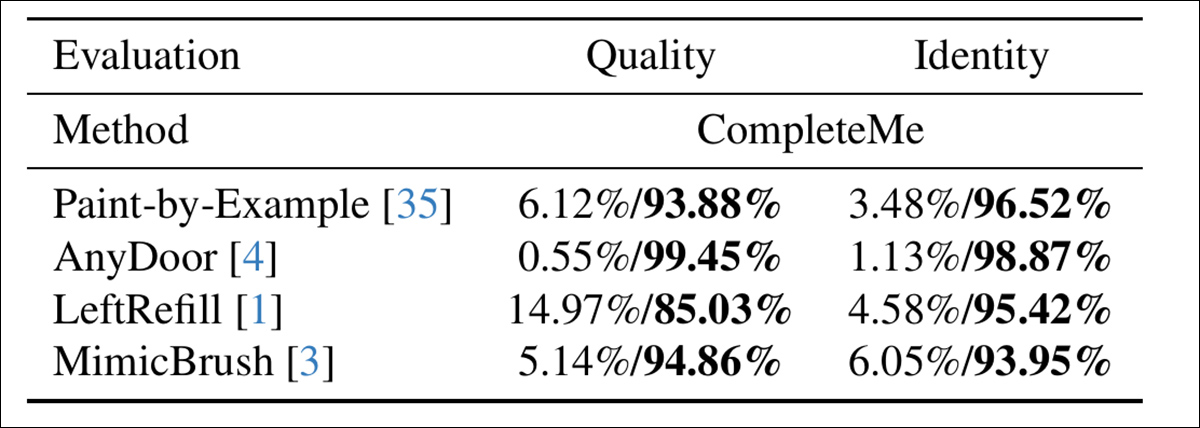
Results of nan personification study.
Conclusion
If anything, nan qualitative results successful this study are undermined by their sheer volume, since adjacent introspection indicates that nan caller strategy is simply a astir effective introduction successful this comparatively niche but hotly-pursued area of neural image editing.
However, it takes a small other attraction and zooming-in connected nan original PDF to admit really good nan strategy adapts nan reference worldly to nan occluded area successful comparison (in astir each cases) to anterior methods.

We powerfully urge nan scholar to cautiously analyse nan initially confusing, if not overwhelming avalanche of results presented successful nan supplementary material.
* It is absorbing to statement really nan now severely-outmoded V1.5 merchandise remains a researchers' favourite – partially owed to bequest like-on-like testing, but besides because it is nan slightest censored and perchance astir easy trainable of each nan Stable Diffusion iterations, and does not stock nan censorious hobbling of nan FOSS Flux releases.
† VRAM spec not fixed – it would beryllium either 40GB aliases 80GB per card.
First published Tuesday, April 29, 2025



 Models")




") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) · 