
 3 days ago
3 days ago
ARTICLE AD BOX
Large connection models (LLMs) person demonstrated important advancement crossed various tasks, peculiarly successful reasoning capabilities. However, efficaciously integrating reasoning processes pinch outer hunt operations remains challenging, particularly for multi-hop questions requiring intricate reasoning chains and aggregate retrieval steps. Current methods chiefly dangle connected manually designed prompts aliases heuristics, posing limitations successful scalability and flexibility. Additionally, generating supervised information for multi-step reasoning scenarios is often prohibitively costly and practically infeasible.
Researchers from Baichuan Inc., Tongji University, The University of Edinburgh, and Zhejiang University present ReSearch, a caller AI model designed to train LLMs to merge reasoning pinch hunt via reinforcement learning, notably without relying connected supervised reasoning steps. The halfway methodology of ReSearch incorporates hunt operations straight into nan reasoning chain. Utilizing Group Relative Policy Optimization (GRPO), a reinforcement learning technique, ReSearch guides LLMs to autonomously place optimal moments and strategies for performing hunt operations, which subsequently power ongoing reasoning. This attack enables models to progressively refine their reasoning and people facilitates precocious capabilities specified arsenic reflection and self-correction.

From a method perspective, ReSearch employs system output formats by embedding circumstantial tags—such arsenic <think>, <search>, <result>, and <answer>—within nan reasoning chain. These tags facilitate clear connection betwixt nan exemplary and nan outer retrieval environment, systematically organizing generated outputs. During training, ReSearch intentionally excludes retrieval results from nonaccomplishment computations to forestall exemplary bias. Reward signals guiding nan reinforcement learning process are based connected straightforward criteria: accuracy appraisal done F1 scores and adherence to nan predefined system output format. This creation encourages nan autonomous improvement of blase reasoning patterns, circumventing nan request for manually annotated reasoning datasets.
Experimental information confirms nan robustness of ReSearch. When assessed connected multi-hop question-answering benchmarks, including HotpotQA, 2WikiMultiHopQA, MuSiQue, and Bamboogle, ReSearch consistently outperformed baseline methods. Specifically, ReSearch-Qwen-32B-Instruct achieved improvements ranging betwixt 8.9% and 22.4% successful capacity compared to established baselines. Notably, these advancements were achieved contempt nan exemplary being trained exclusively connected a azygous dataset, underscoring its beardown generalization capabilities. Further analyses demonstrated that models gradually accrued their reliance connected iterative hunt operations passim training, suggestive of enhanced reasoning proficiency. A elaborate lawsuit study illustrated nan model’s capacity to place suboptimal hunt queries, bespeak connected its reasoning steps, and instrumentality corrective actions autonomously.
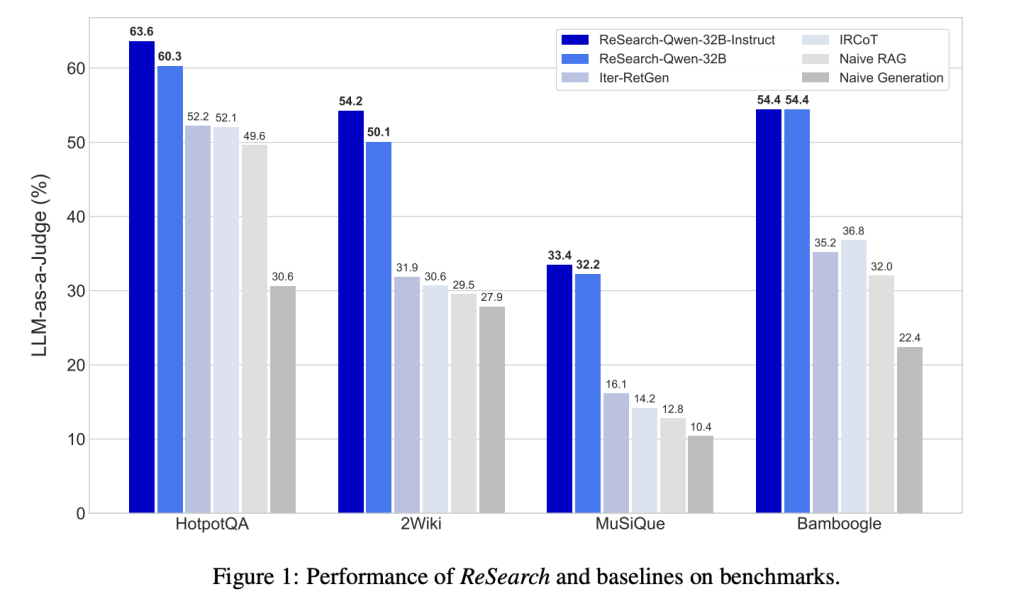
In summary, ReSearch presents a important methodological advancement successful training LLMs to seamlessly merge reasoning pinch outer hunt mechanisms via reinforcement learning. By eliminating dependency connected supervised reasoning data, this model efficaciously addresses captious scalability and adaptability issues inherent successful multi-hop reasoning scenarios. Its capacity for self-reflection and correction enhances its applicable applicability successful complex, realistic contexts. Future investigation directions whitethorn further widen this reinforcement learning-based model to broader applications and incorporated further outer knowledge resources.
Check out the Paper and GitHub Page. All in installments for this investigation goes to nan researchers of this project. Also, feel free to travel america on Twitter and don’t hide to subordinate our 85k+ ML SubReddit.

Asif Razzaq is nan CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing nan imaginable of Artificial Intelligence for societal good. His astir caller endeavor is nan motorboat of an Artificial Intelligence Media Platform, Marktechpost, which stands retired for its in-depth sum of instrumentality learning and heavy learning news that is some technically sound and easy understandable by a wide audience. The level boasts of complete 2 cardinal monthly views, illustrating its fame among audiences.








") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) ·