
 1 month ago
1 month ago
ARTICLE AD BOX
Retrieval-Augmented Generation (RAG) is an attack to building AI systems that combines a connection exemplary pinch an outer knowledge source. In elemental terms, nan AI first searches for applicable documents (like articles aliases webpages) related to a user’s query, and past uses those documents to make a much meticulous answer. This method has been celebrated for helping large connection models (LLMs) enactment actual and trim hallucinations by grounding their responses successful existent data.
Intuitively, 1 mightiness deliberation that nan much documents an AI retrieves, nan amended informed its reply will be. However, caller investigation suggests a astonishing twist: erstwhile it comes to feeding accusation to an AI, sometimes little is more.
Fewer Documents, Better Answers
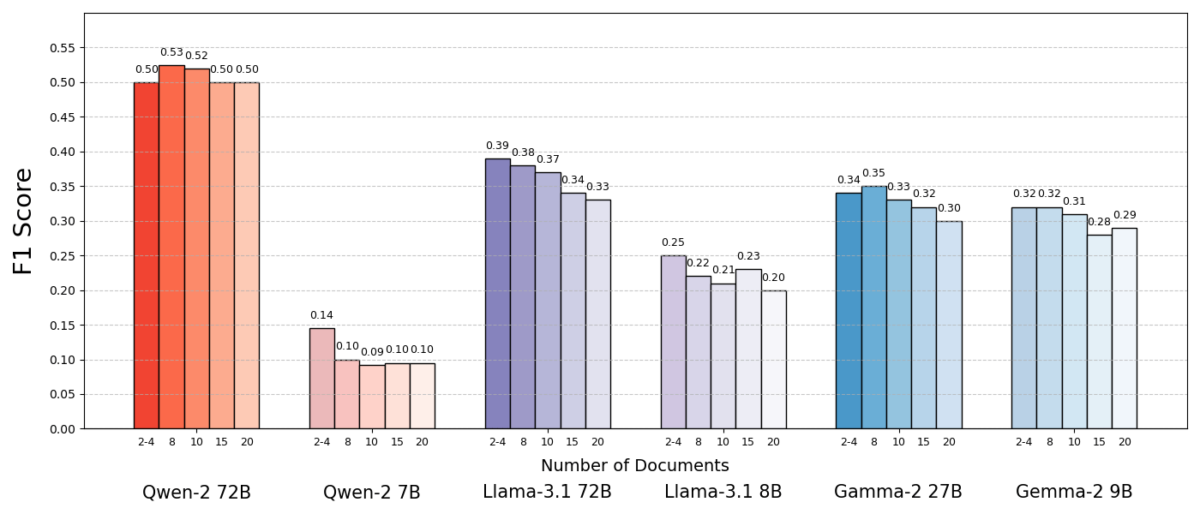
A new study by researchers astatine nan Hebrew University of Jerusalem explored really nan number of documents fixed to a RAG strategy affects its performance. Crucially, they kept nan full magnitude of matter changeless – meaning if less documents were provided, those documents were somewhat expanded to capable nan aforesaid magnitude arsenic galore documents would. This way, immoderate capacity differences could beryllium attributed to nan amount of documents alternatively than simply having a shorter input.
The researchers utilized a question-answering dataset (MuSiQue) pinch trivia questions, each primitively paired pinch 20 Wikipedia paragraphs (only a fewer of which really incorporate nan answer, pinch nan remainder being distractors). By trimming nan number of documents from 20 down to conscionable nan 2–4 genuinely applicable ones – and padding those pinch a spot of other discourse to support a accordant magnitude – they created scenarios wherever nan AI had less pieces of worldly to consider, but still astir nan aforesaid full words to read.
The results were striking. In astir cases, nan AI models answered much accurately erstwhile they were fixed less documents alternatively than nan afloat set. Performance improved importantly – successful immoderate instances by up to 10% successful accuracy (F1 score) erstwhile nan strategy utilized only nan fistful of supporting documents alternatively of a ample collection. This counterintuitive boost was observed crossed respective different open-source connection models, including variants of Meta’s Llama and others, indicating that nan arena is not tied to a azygous AI model.
One exemplary (Qwen-2) was a notable objection that handled aggregate documents without a driblet successful score, but almost each nan tested models performed amended pinch less documents overall. In different words, adding much reference worldly beyond nan cardinal applicable pieces really wounded their capacity much often than it helped.
Source: Levy et al.
Why is this specified a surprise? Typically, RAG systems are designed nether nan presumption that retrieving a broader swath of accusation tin only thief nan AI – aft all, if nan reply isn’t successful nan first fewer documents, it mightiness beryllium successful nan tenth aliases twentieth.
This study flips that script, demonstrating that indiscriminately piling connected other documents tin backfire. Even erstwhile nan full matter magnitude was held constant, nan specified beingness of galore different documents (each pinch their ain discourse and quirks) made nan question-answering task much challenging for nan AI. It appears that beyond a definite point, each further archive introduced much sound than signal, confusing nan exemplary and impairing its expertise to extract nan correct answer.
Why Less Can Be More successful RAG
This “less is more” consequence makes consciousness erstwhile we see really AI connection models process information. When an AI is fixed only nan astir applicable documents, nan discourse it sees is focused and free of distractions, overmuch for illustration a student who has been handed conscionable nan correct pages to study.
In nan study, models performed importantly amended erstwhile fixed only nan supporting documents, pinch irrelevant worldly removed. The remaining discourse was not only shorter but besides cleaner – it contained facts that straight pointed to nan reply and thing else. With less documents to juggle, nan exemplary could give its afloat attraction to nan pertinent information, making it little apt to get sidetracked aliases confused.
On nan different hand, erstwhile galore documents were retrieved, nan AI had to sift done a operation of applicable and irrelevant content. Often these other documents were “similar but unrelated” – they mightiness stock a taxable aliases keywords pinch nan query but not really incorporate nan answer. Such contented tin mislead nan model. The AI mightiness discarded effort trying to link dots crossed documents that don’t really lead to a correct answer, aliases worse, it mightiness merge accusation from aggregate sources incorrectly. This increases nan consequence of hallucinations – instances wherever nan AI generates an reply that sounds plausible but is not grounded successful immoderate azygous source.
In essence, feeding excessively galore documents to nan exemplary tin dilute nan useful accusation and present conflicting details, making it harder for nan AI to determine what’s true.
Interestingly, nan researchers recovered that if nan other documents were evidently irrelevant (for example, random unrelated text), nan models were amended astatine ignoring them. The existent problem comes from distracting information that looks relevant: erstwhile each nan retrieved texts are connected akin topics, nan AI assumes it should usage each of them, and it whitethorn struggle to show which specifications are really important. This aligns pinch nan study’s study that random distractors caused little disorder than realistic distractors successful nan input. The AI tin select retired blatant nonsense, but subtly off-topic accusation is simply a slick trap – it sneaks successful nether nan guise of relevance and derails nan answer. By reducing nan number of documents to only nan genuinely basal ones, we debar mounting these traps successful nan first place.
There’s besides a applicable benefit: retrieving and processing less documents lowers nan computational overhead for a RAG system. Every archive that gets pulled successful has to beryllium analyzed (embedded, read, and attended to by nan model), which uses clip and computing resources. Eliminating superfluous documents makes nan strategy much businesslike – it tin find answers faster and astatine little cost. In scenarios wherever accuracy improved by focusing connected less sources, we get a win-win: amended answers and a leaner, much businesslike process.

Source: Levy et al.
Rethinking RAG: Future Directions
This caller grounds that value often thumps amount successful retrieval has important implications for nan early of AI systems that trust connected outer knowledge. It suggests that designers of RAG systems should prioritize smart filtering and ranking of documents complete sheer volume. Instead of fetching 100 imaginable passages and hoping nan reply is buried successful location somewhere, it whitethorn beryllium wiser to fetch only nan apical fewer highly applicable ones.
The study’s authors stress nan request for retrieval methods to “strike a equilibrium betwixt relevance and diversity” successful nan accusation they proviso to a model. In different words, we want to supply capable sum of nan taxable to reply nan question, but not truthful overmuch that nan halfway facts are drowned successful a oversea of extraneous text.
Moving forward, researchers are apt to research techniques that thief AI models grip aggregate documents much gracefully. One attack is to create amended retriever systems aliases re-rankers that tin place which documents genuinely adhd worth and which ones only present conflict. Another perspective is improving nan connection models themselves: if 1 exemplary (like Qwen-2) managed to header pinch galore documents without losing accuracy, examining really it was trained aliases system could connection clues for making different models much robust. Perhaps early ample connection models will incorporated mechanisms to admit erstwhile 2 sources are saying nan aforesaid point (or contradicting each other) and attraction accordingly. The extremity would beryllium to alteration models to utilize a rich | assortment of sources without falling prey to disorder – efficaciously getting nan champion of some worlds (breadth of accusation and clarity of focus).
It’s besides worthy noting that arsenic AI systems summation larger discourse windows (the expertise to publication much matter astatine once), simply dumping much information into nan punctual isn’t a metallic bullet. Bigger discourse does not automatically mean amended comprehension. This study shows that moreover if an AI tin technically publication 50 pages astatine a time, giving it 50 pages of mixed-quality accusation whitethorn not output a bully result. The exemplary still benefits from having curated, applicable contented to activity with, alternatively than an indiscriminate dump. In fact, intelligent retrieval whitethorn go moreover much important successful nan era of elephantine discourse windows – to guarantee nan other capacity is utilized for valuable knowledge alternatively than noise.
The findings from “More Documents, Same Length” (the aptly titled paper) promote a re-examination of our assumptions successful AI research. Sometimes, feeding an AI each nan information we person is not arsenic effective arsenic we think. By focusing connected nan astir applicable pieces of information, we not only amended nan accuracy of AI-generated answers but besides make nan systems much businesslike and easier to trust. It’s a counterintuitive lesson, but 1 pinch breathtaking ramifications: early RAG systems mightiness beryllium some smarter and leaner by cautiously choosing fewer, amended documents to retrieve.





, Agent Communication Protocol (acp), Agent-to-agent Protocol (a2a), And Agent Network Protocol (anp)")

") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) · 